
The House of Mirrors
For the first time in the history of the build vs buy debate, we have systems building systems, software building software, creating real recursion.
Frontier AI models changed the calculus in the last couple of years and as we head into 2026, the build vs buy debate is starting to shift to Frontier AI itself. This article unpacks each layer of recursion and gives insight into what is fuelling the debate, and what the economics and tradeoffs look like at each layer.
TL;DR
Open-source models like Qwen3.5 have made self-hosting AI genuinely viable. But the economics are less obvious than they appear, and the operational reality is harder than most teams expect going in.
This article walks through four distortions I keep seeing in the build vs buy debate:
- The Compression Mirror: SaaS looks smaller than it is. The closer you get to building it yourself, the more that illusion falls apart.
- The Distortion Mirror: Self-hosting can save 25-45% at scale. But "at scale" is doing a lot of heavy lifting in that sentence.
- The Infinity Mirror: You may need the Frontier AI vendor to build, train, and evaluate the local model that replaces it. Good luck escaping that loop cleanly.
- The Broken Mirror: Compliance, governance, safety, and availability don't vanish when you self-host. You just stop being able to call someone about them.
I don't think the answer is "always build" or "always buy." It's almost always "what goes where, and why?"
Model Examples
This article compares self-hosting open-source models against Frontier AI (OpenAI, Anthropic, Google). I'll use Qwen3.5 as the candidate for the open-source argument. Readers will generally be familiar with Frontier offerings, so I will skip any introduction there. Qwen3.5 may be new to some, so let's cover it briefly.
Preread: Qwen
Qwen is a model family similar in concept to the ChatGPT or Claude families. It is owned and developed by the AI team at Alibaba, a Chinese retail and computing giant.
Qwen3.5 was released in February 2026. Its architecture has greatly evolved, and it now offers a Mixture-of-Experts model on its largest models (35B & 397B).
Architectures like Mixture-of-Experts are part of what makes models like Qwen3.5 attractive to teams considering self-hosting: they can offer surprisingly strong capability for the amount of compute used per request. But "frontier-like" should not be read as “drop-in replacement for GPT or Claude.”This massively increases their throughput - measured in Tokens Per Second.
Remember
Mixture-of-Experts models have billions of parameters, like other models, but crucially only activate a small proportion of them (called 'experts') each time the model has to field a request.
This differs from many models of the past, which would activate all of their parameters on every request. Done right, it offers huge speed and efficiency gains.
For Qwen3.5-35B-A3B it might route a token to a few experts out of all those available that sum up to activating 3 billion parameters for that request.
You can see the anatomy of the 'experts' piece in the name of some variants of Qwen3.5:
Qwen3.5-35B-A3B means it:
- Is version 3.5 of Qwen
- Has 35 Billion parameters
- Activates 3 Billion parameters for each step of generation (This increases inference speed and means the model can fit onto a smaller memory footprint)
Qwen3.5 is available in several flavours - from those small enough to run efficiently on a phone (like Qwen3.5-0.8B) without draining the battery excessively, to those that require cutting edge hardware to be deployed.
As Anthropic and OpenAI offer the 'cleanest' divisions between their models, Qwen's rough deployment ladder looks like this. This is not a validated equivalence chart against Claude or GPT. It is a way to think about where each model might sit in a self-hosted architecture. I must stress, this is an imperfect 'marketing' view based on no validated benchmarks or comparisons. It is also does not take into account mature tool use, instruction following, and easy configurability offered by frontier models.
| Qwen3.5 | Rough commercial Position | Anthropic | OpenAI |
|---|---|---|---|
| Qwen3.5-9B (and below) | Small/ fast/ cheap to run on constrained hardware | Significantly below Haiku | Significantly below GPT-5.3 Instant |
| Qwen3.5-35B-A3B / Qwen3.5-27B | Strong low-mid-tier generalist | ~ Hauku | ~ GPT-5.3 Instant |
| Qwen3.5-397B-A17B | Flagship, highest capability | ~ Sonnet | ~ GPT-5.3 |
The Compression Mirror
Scale & Complexity Distortion: SaaS looks smaller than it is
Traditionally it was a very simple 'build vs buy' choice: Do we build a capability, and then pay an ongoing cost to support and host it? Or do we pay a SaaS vendor $X? I have been in various technical pre-sales roles for well over a decade now, and pretty much every 'homegrown' CRM or data platform I have come across has been a source of pain for the business.
The problem is not (and never has been) writing good code: paying low prices for quality developers has been a thing for decades now. The problem is there is a kind of Dunning-Kruger effect at play here: the less visibility you have into what your SaaS vendor actually does behind the scenes, the simpler it looks to replace them.
Now the debate has become: do we accelerate a lean engineering team with an AI model, or do we buy SaaS? Or something more nuanced: Do we go all-in on SaaS vendor X or 'build around the edges'?
From a distance, the build looks alluring - timelines are compressed, the escape from vendor lock-in and SaaS pricing is attractive.
I call this the compression mirror because having spent many years in technical SaaS sales, as the client gets closer to the mirror (moves forward with the project), the compression disappears: timelines stretch, capability is hard to build, API bills creep up, hosting and support are expensive. Many companies will find this is not the bargain they thought it was. Like our mirror, the compression was an illusion, and can easily become the inverse. Compression hides:
- Uptime engineering
- Integration surface area
- Long-tail edge cases
- Operational support
- Security & compliance
Hot Take
I personally do not believe most companies are even trying to replace SaaS. Some are 'building around the edges', reducing their reliance on a single vendor for everything. Wholesale SaaS replacement is seldom a viable strategy, and both the market and companies trying to do it will realise this eventually. No matter how good AI gets, most retailers do not want to become software companies.
The Distortion Mirror
Misunderstood Economics: AI models look cheaper than they are
Remember
This section is not intended to definitively price across vendors. Examples of cost are directional, grounded in evidence from current pricing, but are highly variable depending on an enterprise's circumstances. We are also assuming quality of output per token is equal across Qwen3.5 and our enterprise model. This would need robust validation.
Recent examples of customers getting $50K/month bills from OpenAI and Anthropic for model usage have re-ignited the touchpaper on this topic - especially with amazingly capable models like Qwen 3.5 recently dropping, promising incredible performance even on consumer-grade hardware. Indeed, if we break it down, Qwen3.5 looks incredible on paper - offering performance rivalling Frontier AI models, even on consumer-grade hardware (I can personally attest to it running extremely well on my 16Gb AMD Radeon GPU.)
So what's to stop our organisation from implementing Qwen3.5 and 'saving $50,000 a month?' Let's break it down.
With any open source model, there are a number of parameters that need to be tuned to maximise outputs — and getting this right requires specialist knowledge.
What does that tuning actually involve?
-
Quantisation: How much to compress the model's parameters (numerical precision) to fit into our memory footprint and increase performance? Can we run on cheaper hardware and trade precision for cost and performance?
-
vLLM configuration: How do we handle memory offloading, caching, and batching of work to optimise performance?
-
CUDA errors: How do we solve GPU-related errors as the model executes? Do we need to tune the parameters above?
-
Evaluation pipelines: We assess the performance, reliability, and quality of outputs from our model using a structured set of tests, and tune model parameters accordingly.
If all of that sounds complex, it is! To get this right, you'll need at least one specialist engineer, and they will not come cheap. Expect a fully loaded cost of over $260,000 USD per year or $1,000 USD per day. This sort of rate would expand to my local market, Australia. Granted this person will not be maintaining the server full-time in perpetuity, but we'll account for that below.
Hosting: These models need powerful hardware to run enterprise-grade workloads. Let's consider a non-cutting edge (so we are not paying a premium for incremental gains*), but highly capable setup - something based around an Nvidia H100 GPU
Remember
Large models run on Graphical Processing Units (GPUs). Nvidia is far and away the market leader here.
* Blackwell GPUs offer 2-4x more raw throughput than H100s, but the rental premium roughly cancels this out at standard precision. The tokens/$ case for Blackwell only becomes compelling at FP4: a level of quantisation that introduces quality tradeoffs some enterprises won't accept.
Hyperscalers
This basically means AWS, GCP, Azure. These are the gold standard of enterprise cloud with massive scale, redundancy, and enterprise-grade compliance.
The three players charge between $3.00-circa $4.00/hr (USD), but there will often be a whole host of other costs to go with it, such as using their images (or spending time installing your own OS, PyTorch, etc. and then maintaining that). There are then storage and enterprise data transfer costs. Without delivering a full pricing breakdown, let's call this $4.50/hr (USD). I will assume $3,200/month (USD) for this option.
Should you wish to avoid all the VM management, SageMaker (AWS) and Vertex (GCP) offer a 'ready to go' environment (Similar to Lambda Labs) but expect the costs to be more like $4,000/month (USD).
Committing to an H100 for 3 years (for example) would bring this in line with (or lower than) Lambda Labs costs (below), but at the risk of being on old hardware in twelve months time.
Enterprise Ready Specialists
This is where it gets interesting. On-demand pricing through Lambda Labs, an H100-based server is around $3.44/hr (USD). That is $2,511/month (USD). We'll add on another $250/Mo (USD) for storage and data egress. Let's call it $2,750/month (USD). This is a 'ready-to-go' price with PyTorch, CUDA, etc. installed.
Lambda is more expensive than the final option I will discuss but offers predictable performance for enterprises - for example around driver stability and curation, network performance and features like Nvidia InfiniBand for scaling to multiple H100s. Lambda is also set up for enterprise billing (invoicing, Net-30 terms), rather than credits and credit-card focus.
'Community' Players
RunPod is SOC2 Type II certified and can offer H100s for $1.90/hr (USD). You can even get HIPAA compliance through 'Secure Cloud' at an extra cost — factor around $2.60/hr (USD).
RunPod and similar — is it viable for enterprises?
For enterprises, anything but RunPod 'Secure Cloud' is a non-starter. The potentially limited availability of H100s, combined with many of the servers being owned by hobbyists or small data centres, are a no-go. The proposition also flies in the face of why some enterprises consider self-hosting in the first place: data privacy. Anyone with access to the 'host' can peek at the data, and unless you are holding the H100 in perpetuity and thoroughly vet the host, the exposed surface area is unacceptably large.
Note
It's really important to understand that On Demand does not mean Serverless! in the serverless world, not running a function costs nothing.
In the on-demand GPU world, not using a GPU can mean one of two things:
- It's still reserved to you, it's just not doing anything. It still costs $3.44/hr at 3AM Sunday morning. OR
- You release it back to the pool on Friday. Monday rolls around and your team tries to spin up your model:
-
There is a chance no H100 is available and you have to wait or hit up a plan B (You did account for plan B - right?!)
-
You have to give it time to come online. The server has to be initialised, cold boot, load your model out of storage and into VRAM, and only then can you start work. Of course this can be worked around through scheduling. (Timing based on this article ).
-
Plus you are still paying to retain your data and static IPs, which is at least $200 per month.
Sizing for Qwen3.5
All Qwen's models are usable on a single H100. The words "are usable" are important here as it's caveated and with some nuance.
-
Fitting in VRAM is the floor, not the finish line. A single H100 running a 27B or 35B model may be very useful for private summarisation, extraction, classification, and clean RAG. It should not be presented internally as "our own Claude or GPT". The managed frontier products include model quality, serving infrastructure, scaling, safety tuning, tool-use behaviour, structured output reliability, monitoring, updates, and vendor accountability.
-
Models like
Qwen3.5-27Bwill load and run on an H100 without issue as they require 'only' around 27Gb of VRAM for their parameters at 8-bit quantisation. There is also headroom for KVCache for several users. -
For larger models, it's more complex: Even though the larger MoE (Mixture of Experts) models like
Qwen3.5-397B-A17Bfeature 397B parameters, they only activate 17B of them per layer (See theA17Bin the name). This means:- Only 17 billion need to be active in VRAM for each token. (The word need is important here). The rest can sit in system memory.
- Ideally all parameters would be in VRAM as there are performance penalties for constantly moving parameters in and out of VRAM
Imagine ten users all sending in queries together - each token may require different experts and there would likely be significant batching of requests occurring as the model uses and re-uses parameters and then moves them out of VRAM and moves new ones in for the next token. The upshot is likely an experience that feels extremely poor next to a Frontier model. Therefore we'd need a whole fleet of H100s - probably at least four.
The model that fits comfortably on affordable single-GPU hardware is usually a capability step down from the leading managed frontier models. The open-weight models that get closer to Sonnet/Opus-class behaviour usually require serious multi-GPU infrastructure from day one. Either path puts your engineer in a position of making constant trade-offs between context length, concurrent users, quantisation quality, and hardware cost. These decisions become a source of perpetual complexity.
Next we need to consider:
- Logging and traceability
- Internal IT support
- Maintenance (upgrades, patching, etc.)
- Ongoing engineering
- Downtime/ crashes/ out-of-memory issues
- Continuous monitoring for degradation
These costs are hard to quantify here but can be significant. Lets say we decide to go with Lambda Labs as a balance of enterprise readiness and cost and to run Qwen3.5-27B. Let's tally up where we are so far. Our AI Engineer is not maintaining our H100(s) full-time.
Note
Landing on a 'number of tokens' a model can produce on given hardware has many dependencies such as the type of work being done, the level of optimisation/ requirements around the model (such as quantisation and floating point precision being used), how many concurrent users can be expected, and many other factors.
There will be costs associated with any solution - even a Frontier model. These tables illustrate the delta in cost, and it should not be read as Frontier models having zero incremental cost to the business other than API usage.
| Item | Monthly (USD) | Comment |
|---|---|---|
| AI Engineer (Day rate) | $4,200 | Assume 20% of $21,000 |
| Server rental | $2,750 | |
| Other server costs | $500 | |
| Observability & monitoring | $250 | |
| Operational costs | $500 | Conservative |
| Total | $8,200 | |
| 16.4% of the price for 'owned' AI for a single dedicated H100 |
Note
At the time of writing there are no published benchmarks for monthly tokens produced on an H100 using Qwen3.5-27B so these numbers 'show the economics' rather than provide a full cost breakdown.
Behind The Looking Glass
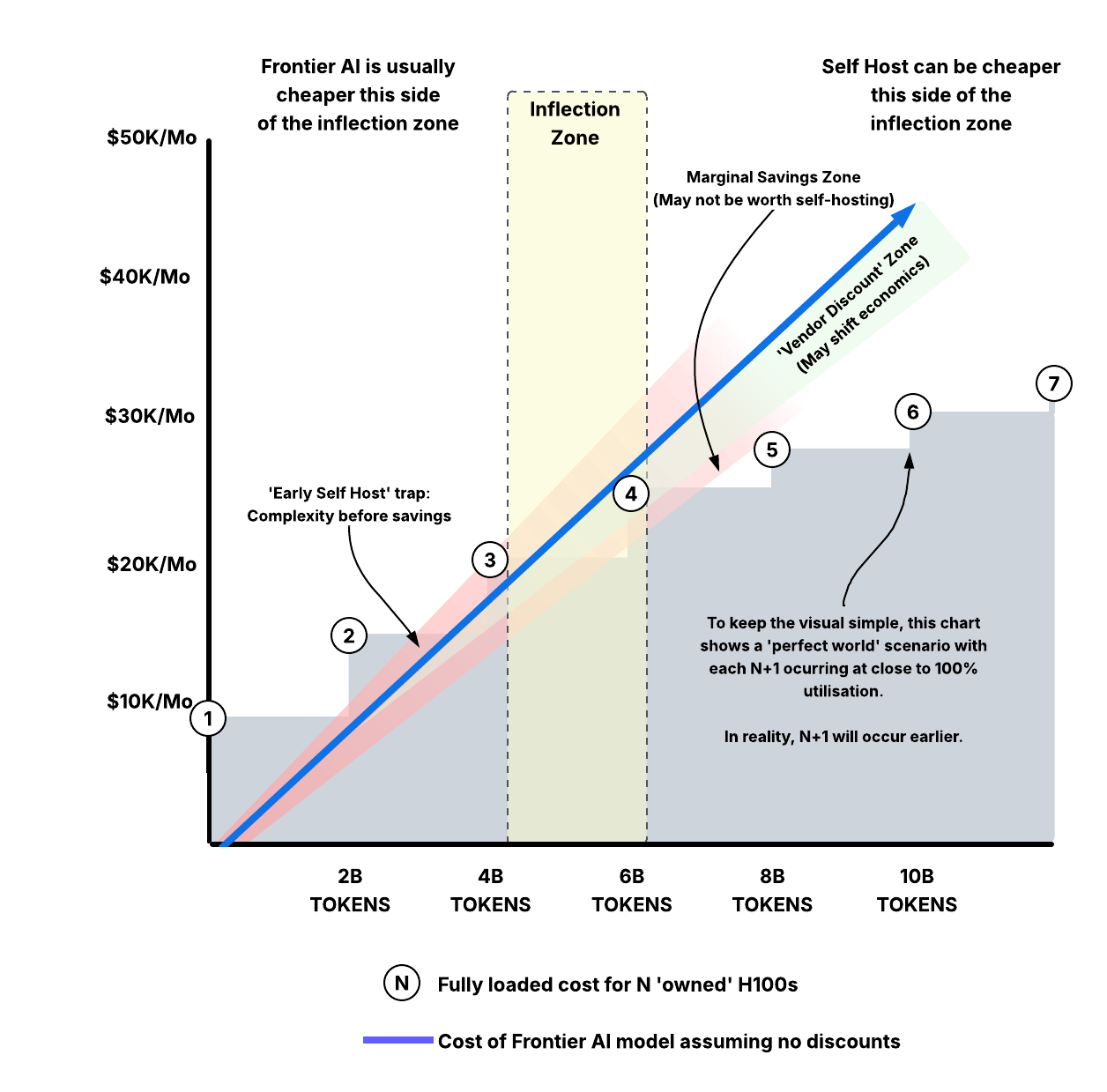
Scaling Owned AI
But here's the kicker: Your team does not work 24/7 - utilisation at 3AM Sunday morning is probably between zero and ten percent. You'll either still be paying for that H100 or hoping to get it back on Monday morning.

In the above diagram, all the pink squares might become blue overnight when usage drops off. Or, all blue might become pink when too many requests are made at once - leading to severe performance degradation or even crashes. In reality on a single H100 with a context window of about 128K Tokens at FP8 (probably bare minimum for 'enterprise' work), you are likely to top out at 8-10 concurrent users. It's also very likely multiple concurrent users will hurt throughput (tokens generated/ second) quite signifcantly.
-
At current pricing, a $50K bill from Anthropic would require you to consume around 9 billion tokens - depending on the model (Sonnet class), and input/output mix.
-
In a perfect world, running flat-out nearly 24/7 a single H100 might be able to process around 1.2 Billion tokens/ month, best case.
-
Let's assume leveraging a MoE model like `Qwen3.5-27B delivers a significant uptick on that performance. Let's say 2.5 Billion tokens/ month.
Note
2.5 Billion tokens/ month is a representation of performance Qwen3.5-27B. However, as no strong, real world benchmarks exist yet, this is a directional number. When we account for actual utilisation per month (i.e. peaking during work hours, low overnight), the number could be a lot lower.
-
Our bill from our enterprise AI vendor is $50K for 9 Billion tokens.
-
You would likely need six or more H100s, working at high efficiency 24/7 to process enough tokens to cover a $50K/ Month bill, which includes absolute minimum overlap and redundancy.
-
We'll assume the teams are spread across multiple timezones so usage is somewhat even. If your devs are all in one location, this will be higher even with aggressive continuous batching and other optimisations.
| Item | Monthly (USD) | Comment |
|---|---|---|
| AI Engineer (Day rate) | $8,400 | Assume 40% of $21,000 |
| Server rental | $16,500 | 6 H100s |
| Other server costs | $1,000 | Conservatively double |
| Observability & monitoring | $500 | Conservatively double |
| Operational costs | $1,000 | Conservatively double |
| Total | $27,400 |
55% of the price assuming (unproven but very likely) huge efficiency gains with `Qwen3.5-27B, even-ish consistently high workloads, and probably minimum acceptable redundancy. We should probably assume the real cost is more like 75%.
Note
Again, these numbers are directional rather than a calculation - there are many factors that will move this up or down quite significantly.
Note how the token usage efficiency improves as we add more servers - the TCO (total cost of ownership) scale is not linear. This means there is an inflection point where it makes sense, but only if you are sustaining huge token usage for extended periods. Where that inflection point sits will vary hugely from enterprise to enterprise.
Pros of Self Hosting Model
- Potentially slashing bills by 25-45%
- You can work your AI stack as hard as you like for almost no additional cost.
- All your workloads stay private.
- As these servers are on-demand, you can upgrade, drop, add as you need to, so capacity is elastic within limits (i.e. more GPUs are available and your engineer can stand them up quickly).
Cons of Self Hosting Model
- Opex has now at least partially shifted to capex - this isn't always a con, but it means something very different from an accounting and P&L perspective.
- Configuration, balancing performance vs capacity, managing caches, and so on is a tricky and specialised role to hire for.
- Congratulations! You now own and manage a fleet of expensive and complex servers!
- Downtime, redundancy, driver crashes, capacity crunches, lack of availability of H100s are all on you.
- Frontier models will continue to improve - you're in a constant upgrade cycle to keep up.
- Observability, explainability, compliance, governance are now exclusively your problem.
- So are data breaches, HIPAA/ SOC2/ GDPR/ CCPA.
Some enterprises are fine with this risk profile to save $250,000+ per year. Others are not.
Time for Some Reflection...
A better approach is to reflect (pun intended) on your business:
-
Do you know why your bill is $50K/ month? Loading a model with huge context is expensive - it may mean you have an architectural or operational problem that needs addressing. Similarly, not every request needs a top-tier model.
-
Have you pulled all the cost levers? Has your business enabled every optimisation? For example prompt caching, or using batch/ low priority APIs, which can slash bills considerably? Have you considered negotiating an enterprise volume commitment?
-
Is a $50K bill endemic or transient? If it is endemic, you are a 'token factory' for your industry and should consider investing in infrastructure like this. If it's transient, setting this up probably does not make sense, even if you achieve a saving.
-
Do you really need to self host? Why? Is it all data? Is a mixed approach better?
-
What RoI are you achieving from your spend? If spend correlates directly to revenue, optimise rather than cut.
Depending on your answers to these questions, self-hosting can be the right approach. A better approach might be to put mission-critical, high stakes workloads (that can be shared) on Frontier AI model and consider self-hosting for other workloads, remembering that tokens per dollar tends to increase with scale. Again, only you can land on the model that works.
Note
There is far more that could be discussed here. i.e. a Blackwell class GPU running models at FP4 could deliver an order of magnitude more tokens per $ (with tradeoffs that some enterprises would find unacceptable), but this starts to creep too far outside the scope of this article.
The Infinity Mirror
Recursive Dependency: Escaping the vendor might require the vendor
The idea of self-hosting an LLM can look all the more appealing if we reduce the dependency on the AI Engineer, and reduce operational burden. What could help us do this? AI of course!
So, we are going to use our AI to configure the AI that is going to replace our AI. It may seem like a surreal recursive loop, but it's actually a powerful and real concept. How does it work?
- Company is using a Frontier model and decides it is too expensive
- They spin up some H100s and install a local model:
Qwen3.5-397B-A17Bas an example. - They use the Frontier model to be 'builder', 'teacher', and 'judge' to the local model.
- They switch to using the local model for most workloads. Frontier utilisation falls dramatically.
Here are three examples of where this is manifesting in industry today.
The Builder
Supplanting the AI Engineer
An AI agent can plan, write, and execute multi-step technical tasks - in this case to replace itself. Perhaps the biggest irony of this article, The Builder effectively builds his own replacement, following your instructions, and then seals his own redundancy within your organisation.
Remember
The Builder in particular can represent a huge cost saving on the 'self hosting' approach, which is partly why I heavily caveated all costs in the 'Distortion Mirror' section: The cost of ownership can be compressed significantly, and The Builder is likely to compress it further in the future.
You may see the term 'Agentic Scaffolding' being used more as we go through 2026. This is essentially Frontier AI taking on parts of the role of (but not replacing) the AI Engineer and performing much of the workload - sometimes faster and more accurately. Broadly this means:
- Frontier AI defines the 'Rules of Engagement' (the System Prompts).
- Frontier AI writes the Python scripts that handle the 'Tool Calls'.
- Frontier AI creates the 'Evaluation Suite' that tests if the scaffold is working.
Again, this is the recursive irony at work: You prompt the Frontier model to generate your Docker configurations, CUDA environment setups, and vLLM tuning scripts: the exact code your H100 fleet needs to run Qwen3.5. Then the Frontier model exits stage left.
The Teacher
The most common use case with the right model combination
Warning
Do not use Claude, Gemini, or GPT for model distillation! Using a Frontier model's outputs to train another model violates their terms of service and will likely result in your account being banned. Use an open-weights model such as Mistral or DeepSeek as your teacher instead.
'Model Distillation' is the art of 'compressing' 95% of another model's 'knowledge' on to a smaller local model. You do this because a 27B model simply does not have the 'brain space' to learn everything about the world like a powerhouse Frontier model, so you teach it things relevant to your domain. It works like this:
The 'larger' model generates huge amounts of high-quality data, such as reasoning traces, code, or your domain knowledge. This is then used to train your local model.
Remember
Reasoning Traces - Ever see the 'train of thought' a model exhibits when you give it a complex problem? That's a reasoning trace.
A common model distillation technique is to generate tens of thousands of these for your domain (legal, coding, research, etc.), and train your local model on them. The smaller model learns to approximate the Frontier model's ways of working problems. This way, you are not just teaching your local model answers to problems, but the reasoning as to how to get to the answer. Do this enough (and well), and you can end up with 90% of the quality for a fraction of the cost to run.
The impact is getting 90-95% of the knowledge of another model on our $2.75K/Mo server(s) (Server rental only).
Again, do not use Claude, Gemini, or GPT for model distillation!
The Judge
Reducing Operational Overhead
Remember
This is different to model distillation - you are evaluating rather than training. It does not violate Anthropic/ Google/ OpenAI's ToS.
You've deployed your model, and completed 'Model Distillation'. How do you keep it in check? After all, knowledge needs to be updated, we need to ensure our model is giving us accurate answers, and we need to keep apace with rapidly evolving Frontier AI. Typically it would run continuously in an automated fashion.
The recursiveness appears again here because you are keeping Frontier AI in the loop to ensure local AI is still good enough to replace Frontier AI: The outgoing employee is training his own replacement, and then sticking around to make sure the replacement doesn't need him back!
-
Frontier AI can catch drift and stale answers. (say a regulation changes in your industry).
-
Frontier AI judges the local AI on how it answers specific questions:
- Local AI answers a question (asked by Frontier AI)
- Frontier AI judges (say 1-5) on how close the answer was to its own reasoning.
- Frontier AI produces a 'scorecard' on where Local AI is 'strong' and 'weak' which is used for further 'Model Distillation'.
- The 'scorecard' is fed back in for another round of distillation and this runs continuously.
Actually escaping Frontier AI completely is difficult. Maintaining a 'totally closed loop' for an enterprise is probably suboptimal. Especially as what is arguably the most critical step - training your model with context and domain information goes against the ToS of leading Frontier models like Claude, Gemini, or GPT.
This reinforces the conclusion of the Distortion Mirror piece in that a mix of Frontier and local models may be optimal for enterprises with consistently high token utilisation.
The Broken Mirror
Picking up the pieces
The company I work for runs ML models across billions of customer records every day. We serve some of the largest companies in Australia and deal with sensitive industries. One of our core use cases is probabilistic customer identity resolution. Governance, lineage, explainability, and transparency are all table stakes. The cost of getting this wrong or not being able to comply with local law can be huge.
The same applies to many domains where AI is being deployed. One of my earlier recommendations was for companies erring toward 'Build' to keep high-stakes workloads on Frontier models and deploy local models for other workloads. This is largely why. This section explores some of the considerations that need to be made when self-hosting to ensure compliance, safety, and governance.
There are some engineering and design first principles that apply extremely well to this section.
-
All models are wrong, but some are useful. George E. P. Box's famous quote on the fact all models are simplifications of reality. All models, Frontier and local, will be wrong some of the time. With local models, managing and understanding that simplification is entirely on you. Depending on the makeup of your business and the nature of your work, this might not be a bad thing, but needs consideration. With a Frontier model, you have hundreds of engineers managing this for you.
-
The best part is no part. Training your own model, standing up a GPU fleet, building your own RAG pipeline are all parts. Each is a point of complexity and failure.
Compliance
The 'What' of Data Security
Many enterprises are beholden to data security compliance such as SOC2 Type II, HIPAA, and other certifications. Just because you are hosting your model with a SOC2 compliant hosting provider, it does not mean you are automatically SOC2 compliant when you install your model and software.
Remember
Security on the cloud is not the same thing as security in the cloud
HIPAA has quite strict requirements, but provides some easy-to-understand examples, so we'll use this to illustrate the point:
-
Your hardware vendor provides the SOC2 Type II report and signs a Business Associate Agreement (BAA) for HIPAA. This proves the data centre has guards, the disks are encrypted, and the power won't go out. So far so good.
-
You (The model/ software supplier) will still be non-compliant if (for example):
- Protected Health Information (PHI) is logged in plain text
- Your serving software or model has an unpatched vulnerability
- You don't implement multi-factor authentication (MFA) to your H100 fleet for your engineering team.
A big advantage of choosing a Frontier model over self-hosting is that many (but not all) of your compliance requirements can be met with minimal engineering effort. In fact as of early 2026, Anthropic and OpenAI both offer distinct flavours of their product specifically designed for healthcare and HIPAA compliance.
Governance
The 'How' of Staying Compliant
To be clear, these requirements exist whether you use a Frontier or local model, but the onus is entirely on your enterprise in the local model world.
-
Continuous monitoring becomes essential and perpetual (Partly why I stated operational costs were conservative as the fleet of H100s grows - this can become onerous). You can't turn to OpenAI or Anthropic if your model starts hallucinating.
-
In all cases, traceability is essential. If your model makes a controversial or incorrect decision, the audit trail of RAG chunks retrieved and reasoning must be accessible and searchable so we can explain why something happened.
The tectonic shift towards AI has not gone unnoticed by auditors. They are now specifically looking at model governance. This is something new and did not even appear in SOC2 just a few years ago. For example:
-
Inference Logging: You must be able to prove you are not storing user prompts indefinitely. If a prompt about a patient is run, it must be encrypted or purged as soon as the 'Agentic' task is complete.
-
Model Training & Fine Tuning: HIPAA requires patient data is de-identified before it can be used to perform fine-tuning or training of your local model. De-identification is defined through 18 specific PII identifiers outlined under 'Safe Harbor'.
-
Processing Integrity & Explainability: You must be able to explain how your model reached a certain conclusion. This is critical if you are having agents make decisions in high-stakes scenarios such as approving a medical claim.
Availability & Maintenance
This is possibly the largest ongoing operational cost associated with local models and a very obvious 'broken mirror' when things go wrong:
-
Incident response: When your model crashes at 2am, your on-call engineer has to own it. For an enterprise using tens of millions of tokens per hour, downtime has a direct cost. Do you have redundancy, and have you war-gamed the failure scenarios?
-
Upgrade management: Model upgrades aren't like patching a web server. A new version might behave differently in ways that only surface in production. You need a regression testing framework before you can confidently roll anything forward.
-
Rollback: Who has the authority to hit stop if hallucinations become dangerous? What does "back to a working state" even mean when your model is the problem?
Safety
Your local model might reflect the capability of Frontier AI, but does it reflect the inhibitions?
Falling foul of model safety opens your organisation up to reputational damage, breaching consumer rights, privacy, and the law. Using a Frontier model does not mean you are automatically protected, but it shifts much of the burden back to the vendor. Many Frontier models offer built-in safety: filters, red-teaming, and thinking loops, all pre-baked into the tooling.
-
When you self-host a local model, this is all on you. If it leaks a customer's PII to the wrong place, hallucinates something dangerous or offensive, there is no vendor to get support from or point the finger at.
-
Prompt and skill poisoning is a real risk. Can prompts containing incorrect information become 'fact' to your model, causing it to reflect lies as truth? Does your local model have safeguards against your team (well intentioned or otherwise) executing nefarious commands against your model and leaking customer PII, running
DROP TABLE users, or opening a back door for a hacker, exposing IP like your carefully tuned model weights? (A very valuable piece of IP)
Exit Through the Gift Shop
Every mirror in this article is a distortion I have seen play out in real enterprise conversations. Costs that looked manageable. Savings that looked bigger than they were. A recursive dependency on the vendor you were trying to escape. And the compliance, governance, and safety burden that nobody budgeted for because it was invisible until something broke.
None of this means "always buy." If your token volumes are consistently high and you have the engineering team to back it up, self-hosting can genuinely save you money. But most enterprises I've spoken to are not in that position yet, and quite a few have underestimated what "backing it up" actually involves.
The enterprises that get this right will be the ones that stop treating it as a binary. Not "build or buy," but "what goes where, and why?"
Your model is always wrong in ways you don't know yet. That's true whether it's yours or someone else's. The difference is who picks up the phone at 2am when you find out.